|
|
IVILAB Undergraduate Research |
|
What the computer vision lab does. Computer vision is about algorithms for understanding images (and video). Our approach is to develop semantic representations (models) for what is relevant to real problems, and infer the particulars of the models from image data (the "evidence"). We apply this approach to understanding objects and scenes, human activities (from video), biological structure from images, and web images with captions. In addition we apply computer vision methods to make educational video more accessible (the SLIC project), and we apply our inference and modeling experience to biological problems such a population genetics where the data is molecular (not images). If any of these topics seem interesting to you, read on!
Life in the computer vision lab as an undergraduate researcher. Undergraduate researchers working with the computer vision group are paired up with one or more graduate student mentors based on which project(s) they become involved with. The vision group follows a model that integrates teaching and mentoring, tasks where undergraduates can be productive relatively quickly (e.g., data collection, labeling/marking images, and straight forward programming tasks), and longer range research work where graduate students invest time to guide undergraduates on research projects. Here the expectation is that undergraduate researchers will become invaluable to their project after some time, which has proven true on multiple occasions. The computer vision group is an especially supportive, friendly, and welcoming research group. Undergraduates are encouraged to take part in all lab activities. Active undergraduates typically have desk space with other vision students which further helps undergraduates become productive in research.
Training. The vision group runs training seminar sequences such as the summer "boot camp" where we train new students on the vision lab computation infrastructure, basic programming in C/C++, effective use of Unix, and vision lab software development conventions. Additional training sessions, either during the academic year, or on different topics, are arranged as needed. When there is interest, we run a weekly vision seminar that is focused at the undergraduate level (link to the especially well organized 2009 version). Finally, undergraduate research students are encouraged to attend our ongoing vision meetings where we discuss papers and ideas related to computer vision.
Publishing. Undergraduate researchers working with the vision group have a great record of contributing sufficiently to research projects that they become authors on papers. So far, twelve undergraduates have been authors on nineteen vision lab papers and three abstracts. Click here for the list.
Outreach. The vision group undertakes a number of broader education/outreach activities, and we have had the good fortune of lots of help from undergraduates. For example, undergraduates who work with us in the summer are strongly encouraged to help out with our Integration of Science and Computing (ISC) sumer camp, which is a lot fun and very rewarding.
Vision lab undergraduate researchers past and present. Students who have participated in vision lab as undergraduates include Matthew Johnson (honor's student, graduated December 2003), Abin Shahab (honor's student, graduated May 2004), Ekatarina (Kate) Taralova (now at CMU), Juhanni Torkkola (now at Microsoft), Andrew Winslow (now at Tufts), Daniel Mathis, Mike Thompson, Sam Martin, Johnson Truong (now at SMU), Andrew Emmott (headed to Oregon State), Ken Wright, Steve Zhou, Phillip Lee, James Magahern, Emily Hartley, Steven Gregory, Bonnie Kermgard, Gabriel Wilson, Alexandar Danehy, Daniel Fried, Joshua Bowdish, Lui Lui, Alexander Danehy, and Ben Dicken.
Further information. Undergraduates interested in the vision lab's research should contact Kobus by E-mail (kobus AT sista DOT arizona DOT edu), or the contact person for specific projects. Some of our projects that enjoyed the help of undergraduates are showcased below. Additional vision lab projects are listed on a page linked here. All vision lab projects have potential to provide good undergraduate research experience.
The image(*) to the right shows undergraduate Emily Hartley determining the
geometry of an indoor scene and the parameters of the camera that took the
picture of the scene. Such data is
critical for both training and validating systems that automatically infer scene
geometry, the camera parameters, the objects within the scene, and their
location and pose.
|

|
||
To the right is a screen shot of the SLIC educational video browsing system which
is an excellent project for undergraduates interested in multimedia.
For more information see the
SLIC project page,
or contact
Yekaterina (Kate) Kharitoova
(ykk AT email DOT arizona DOT edu) for more
information. SLIC has led to several publications with undergraduate authors,
and currently two undergraduates are working on it.
|
|
||
There are now millions of images on-line with associated text (e.g., captions).
Information in captions is either redundant (e.g., the word dog occurs, and the dog is
obvious) or complementary (e.g., there is sky above the dog, but it is not mentioned).
Redundant information allows us to train machine learning methods to predict one
of these modalities from the other. Alternatively, complementary information in
the modalities can disambiguate uncertainty (see "Word Sense Disambiguation with
Pictures" below), or provide for combined visual and textual searching and data
mining.
Under the guidance of
PHD student
Luca del Pero,
undergraduates Phil Lee, James Magahern, and Emily
Hartley have contributed to research on using object detectors to improve the
alignment of natural language captions to image data, which has already led to a
publication for them. For more information on this project, contact Luca del
Pero (delpero AT cs DOT arizona DOT edu).
|
|
||
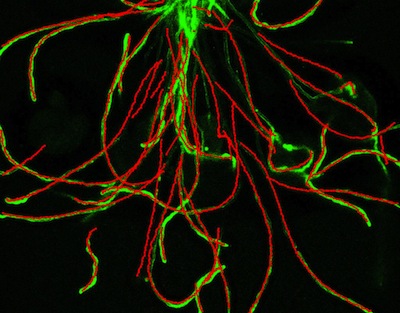
Simultaneously tracking many objects with overlapping trajectories is hard
because you do not know which detections belong to which objects. The vision lab
has developed a new approach to this problem and has applied it to several kinds
of data. For example, the image to the right shows tubes that are growing out of
pollen specs (not visible) towards ovules (out of the picture) in an
|
|
||
CAD models provide the 3D structure of many man made objects such as machine
parts. This projects aims to find objects in images based on these models.
However, since the data is most readily available as triangular meshes, 3D
features that are useful for matching 2D images must be extracted from mesh
data. Undergraduate Emily Hartley has contributed software for this task, and
undergraduate Andrew Emmott has contributed software for matching extracted 3D
features to 2D images. They have been mentored by PHD student
Luca del Pero.
For more information, contact
him (delpero AT
cs DOT arizona DOT edu).
|

|
||
Quantifying plant geometry is critical for understanding how subtle details in
form are caused by molecular and environmental changes. Developing automated
methods for determining plant structure from images is motivated by the
difficulty of extracting these details by human inspection, together with the
need for high throughput experiments where we can test against a large number of
variables.
|



|
||
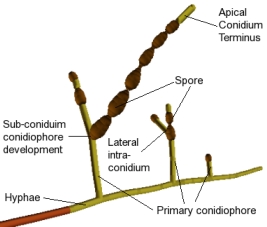
To the right is a labeled model of the fungus Alternaria generated by a
stochastic L-system built by undergraduate researcher
Kate Taralova.
For more information, follow this
link.
|
|
Many words in natural language are ambiguous as illustrated here by the word
"bank". Typically, resolving such ambiguity is attempted by looking at nearby
words in the passage. Computer vision lab undergraduate researcher Matthew Johnson played a key role in
the development of a novel method for adding information from accompanying
illustrations to help reduce the ambiguity. The system learns from a data base
of images that certain word senses (e.g., meanings of bank found with outdoor
photos), are associated with certain kinds of image features. This association
is then used to incorporate information in illustrations to help disambiguate
the word under consideration. This work led to two publications for Matthew.
|

|
These three images illustrate work by computer science students on
a UA multi-department effort to compete in international aerial robotics
competition which is largely an event for undergraduates. Here computer
controlled planes and/or helicopters work towards accomplishing a mission
specified by the contest organizers. Part of the current task is to find a
building having a particular symbol on it (left), and identify the doors and
windows of that building, and then identify which doors and windows are open so
that a sub-vehicle can be launched through the portal. The middle figure shows
the symbol identification software being tested from a moving vehicle to
simulate flight. The far right figure shows a view from the computer science
department with lines found in this image and the matching lines found in a
companion image. The students use the shift (shown in green) between matching
edges to estimate the distance to the edge, which is used to help analyze the
structures. Images provided by undergraduate researcher
Ekatarina (Kate) Taralova (now at CMU).
|



|
A screen shot of a program for browsing large digital art image databases that
is being developed by undergraduate students in computer science at the U of A.
(Art images courtesy of the Fine Arts Museum of San Francisco).
Contributions to this project have been made by undergraduates
Matthew Johnson and John Bruce.
|
|
Two images which have been segmented by three different methods. U of A
undergraduate students in computer science are involved in research to evaluate
the quality of such methods. Segmentation quality is quantified by the degree to
which the regions are useful to programs which automatically recognize what is
in the images. Contributions have been made by Abin Shahab.
|

|

