WORDS and PICTURES
Image understanding as multi-media translation
|
|
WORDS and PICTURESImage understanding as multi-media translation |
|
|
This work has now spanned more than a decade, and has been picked up in one form
or another by many others. Research in linking words and pictures has two main
motivations:
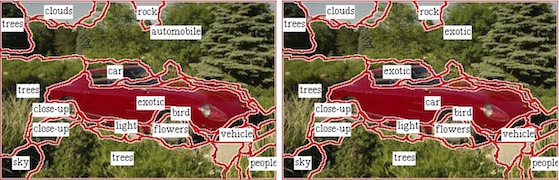
These two problems are closely related because images have both semantic and visual content. Our approach is to build statistical models which "explain" the data in a collection. The data consists of image segment features and words associated with the images. The words may be carefully chosen keywords as in the Corel data set, or free-form text in conjunction with natural language pre-processing. Associated words provide semantic content which is difficult to derive using standard computer vision methods. Conversely, the image features provide information which is often omitted when humans provide the words because it is clearly a visual element. For example, an image of a red rose will not normally have the keyword "red". Thus image features and associated words can complement and even disambiguate each other. Once a statistical model has been built from the data, it can be queried in a probabilistic sense. Specifically, we can ask which images have high probability given the query items, which can be any combination of words and image features. An extreme use of such queries is what we refer to as "auto-illustrate". Given a text passage, we can query an image data base for appropriate images. Going even further, the model can be queried to attach words to pictures--"auto-annotate", which has clear links to recognition. The next step towards recognition is to attach the words to specific image regions. To do this we must solve a correspondence problem while training because which image parts the words refer too is not known, a priori. The situation is analogous to that in learning how to do machine translation translation from aligned bi-texts. Here you have sentences assumed to have the same content, but the word in one does not necessarily translate to the word in the other. Similarly, we approach recognition as translating from visual cues to semantic correlates (words). A key observation which is being exploited in this approach is that as the learning system builds support for which parts of the image are, say, "grass", this reduces the correspondence ambiguity between the other blobs and words. The information to do this is present when the data base is analyzed as a whole. Spatial reasoning. Additional work has looked at constructing more complex models for both the image and language side, and linking the entities in these models. For example, we assume that effective object models include a notion of parts that need to be grouped or analyzed together for recognition. In preliminary work (CVPR 03) we have shown that our approach is suitable for proposing groupings of dissimilar regions. For example, we cannot merge a black and white penguin region with a low level segmentation algorithm, but if both regions are associated with "penguin", we can posit that a better model for "penguin" should incorporate several regions. In collaboration with Peter Carbonetto and Nando de Freitas (ECCV 04), we developed a spatial context model for image grid regions. Language processing. Similarly, more intelligence on the language side can be helpful. The system described above is limited to simple "stuff" nouns. However, if we know that certain words are adjectives and prepositions and further understand their role in sentence structure, then, rather than confuse the learning system, we can use language parsing to help deal with the correspondence ambiguity (TCOR 06). Visual adjectives. One problem that arises in exploiting adjectives in free form caption is that most of them do not correspond to particularly salient visual attributes (e.g., "religious"). Hence we have developed a method to determine the visualness of adjectives to mine web data for candidate useful adjectives (ACM MM 05). Multi-modal disambiguation. Similarly, images can help ground the meaning of language. We have introduced an approach for using images to disambiguate words (AIJ 05). A word like "bank" has many meanings including a financial institution and a break in the terrain as in "river disambiguating words using textual context. We augment text disambiguation methods to use image information from accompanying illustrations. Aligning image elements and caption words is an alternative to simultaneously dealing with two difficult problems: 1) image element and caption word correspondence; and 2) building models semantic units in image. In alignment, we focus on linking image elements with caption words. In other words, we focus on labeling the training data. Having achieved this, we can build models for the semantic units, perhaps with additional iterations of correspondence estimation. While this is implicit in other systems, breaking the problem up in this way has some advantages. For example, we have shown that it can lead to better learning of visual attributes associated with rare words (CVPR 07). Exploiting object detectors. The systems described so far do best in learning the appearance of "stuff" (e.g., sky, water, grass), or certain animals and objects that can be recognized largely by color and texture (e.g., tigers and zebras). Handling shape, while feasible using multi-part models as mentioned above, has proven difficult. Another approach is to exploit the significant work on discriminative models for object category recognition that are trained using images of examples where the objects are prominent. We integrated such detectors into an alignment system, and have verified that they can help. To do this we needed to convert binary (yes/no) detector outputs to probabilities. We further found that using WordNet to allow, say, a bird detector, help resolve sub-categories, such as eagle.
|
|
|
Kobus Barnard David Blei Nando de Freitas Pinar Duygulu David Forsyth Michael Jordan Robert Wilensky Keiji Yanai |
Peter Carbonetto Luca del Pero Quanfu Fan Prasad Gabbur Nikhil Shirihatti Ranjini Swaminathan |
Matthew Johnson Philip Lee James Magaherni Emily Hartley |
Roderic Collins Niels Haering Anthony Hoogs Atul Kanaujia John Kaufhold Ping Wang |